How a GraphQL query fetches data
We've designed our schema and configured our data sources, but our server doesn't know how to use its data sources to populate schema fields. To solve this, we'll define a collection of resolvers.
A resolver is a function that's responsible for populating the data for a single field in your schema. Whenever a client queries for a particular field, the resolver for that field fetches the requested data from the appropriate data source.
A resolver function returns one of the following:
- Data of the type required by the resolver's corresponding schema field (string, integer, object, etc.)
- A promise that fulfills with data of the required type
The resolver function signature
Before we start writing resolvers, let's cover what a resolver function's signature looks like. Resolver functions can optionally accept four positional arguments:
fieldName: (parent, args, context, info) => data;
| Argument | Description |
|---|---|
parent | This is the return value of the resolver for this field's parent (the resolver for a parent field always executes before the resolvers for that field's children). |
args | This object contains all GraphQL arguments provided for this field. |
context | This object is shared across all resolvers that execute for a particular operation. Use this to share per-operation state, such as authentication information and access to data sources. |
info | This contains information about the execution state of the operation (used only in advanced cases). |
Of these four arguments, the resolvers we define will mostly use context. It enables our resolvers to share instances of our LaunchAPI and UserAPI data sources. To see how that works, let's get started creating some resolvers.
Define top-level resolvers
As mentioned above, the resolver for a parent field always executes before the resolvers for that field's children. Therefore, let's start by defining resolvers for some top-level fields: the fields of the Query type.
As src/schema.js shows, our schema's Query type defines three fields: launches, launch, and me. To define resolvers for these fields, open server/src/resolvers.js and paste the code below:
module.exports = {Query: {launches: (_, __, { dataSources }) =>dataSources.launchAPI.getAllLaunches(),launch: (_, { id }, { dataSources }) =>dataSources.launchAPI.getLaunchById({ launchId: id }),me: (_, __, { dataSources }) => dataSources.userAPI.findOrCreateUser(),},};
As this code shows, we define our resolvers in a map, where the map's keys correspond to our schema's types (Query) and fields (launches, launch, me).
Regarding the function arguments above:
All three resolver functions assign their first positional argument (
parent) to the variable_as a convention to indicate that they don't use its value.The
launchesandmefunctions assign their second positional argument (args) to__for the same reason.- (The
launchfunction does use theargsargument, however, because our schema'slaunchfield takes anidargument.)
- (The
All three resolver functions do use the third positional argument (
context). Specifically, they destructure it to access thedataSourceswe defined.None of the resolver functions includes the fourth positional argument (
info), because they don't use it and there's no other need to include it.
As you can see, these resolver functions are short! That's possible because most of the logic they rely on is part of the LaunchAPI and UserAPI data sources. By keeping resolvers thin as a best practice, you can safely refactor your backing logic while reducing the likelihood of breaking your API.
Add resolvers to Apollo Server
Now that we have some resolvers, let's add them to our server. Add the highlighted lines to src/index.js:
const { ApolloServer } = require("apollo-server");const typeDefs = require("./schema");const { createStore } = require("./utils");const resolvers = require("./resolvers");const LaunchAPI = require("./datasources/launch");const UserAPI = require("./datasources/user");const store = createStore();const server = new ApolloServer({typeDefs,resolvers,dataSources: () => ({launchAPI: new LaunchAPI(),userAPI: new UserAPI({ store }),}),});server.listen().then(() => {console.log(`Server is running!Listening on port 4000Explore at https://studio.apollographql.com/sandbox`);});
By providing your resolver map to Apollo Server like so, it knows how to call resolver functions as needed to fulfill incoming queries.
Run test queries
Let's run a test query on our server! Start it up with npm start and return to Apollo Sandbox (which we previously used to explore our schema).
Paste the following query into the Operations panel:
# We'll cover more about the structure of a query later in the tutorial.query GetLaunches {launches {idmission {name}}}
Then, click the Run button. Our server's response appears on the right. See how the structure of the response object matches the structure of the query? This correspondence is a fundamental feature of GraphQL.
Now let's try a test query that takes a GraphQL argument. Paste the following query and run it:
query GetLaunchById {launch(id: "60") {idrocket {idtype}}}
This query returns the details of the Launch object with the id 60.
Instead of hard-coding the argument like the query above, these tools let you define variables for your operations. Here's that same query using a variable instead of 60:
query GetLaunchById($id: ID!) {launch(id: $id) {idrocket {idtype}}}
Now, paste the following into the tool's Variables panel:
{"id": "60"}
Feel free to experiment more with running queries and setting variables before moving on.
Define other resolvers
You might have noticed that the test queries we ran above included several fields that we haven't even written resolvers for. But somehow those queries still ran successfully! That's because Apollo Server defines a default resolver for any field you don't define a custom resolver for.
A default resolver function uses the following logic:
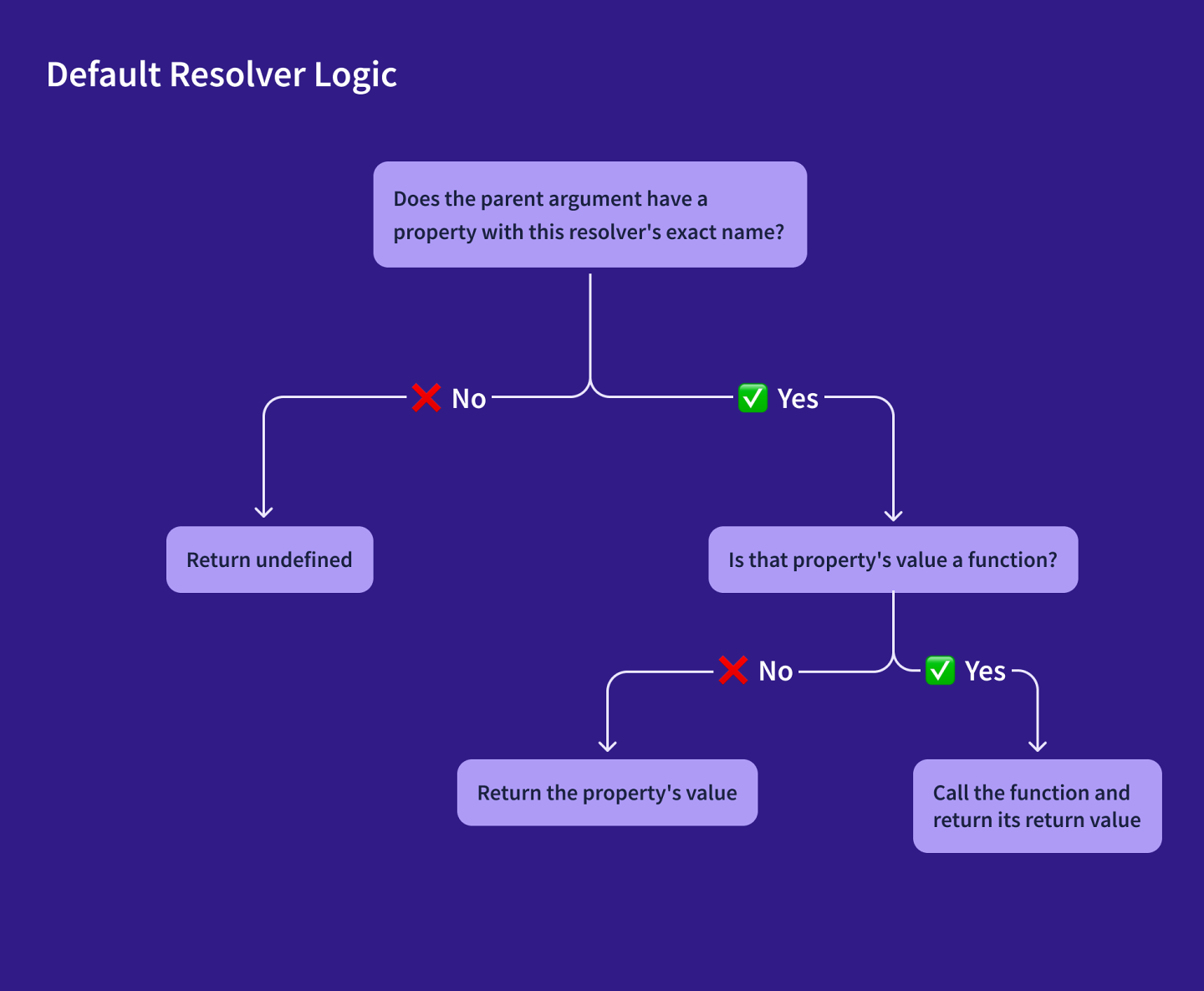
For most (but not all) fields of our schema, a default resolver does exactly what we want it to. Let's define a custom resolver for a schema field that needs one, Mission.missionPatch.
This field has the following definition:
type Mission {# Other field definitions...missionPatch(size: PatchSize): String}
The resolver for Mission.missionPatch should return a different value depending on whether a query specifies LARGE or SMALL for the size argument.
Add the following to your resolver map in src/resolvers.js, below the Query property:
// Query: {// ...// },Mission: {// The default size is 'LARGE' if not providedmissionPatch: (mission, { size } = { size: 'LARGE' }) => {return size === 'SMALL'? mission.missionPatchSmall: mission.missionPatchLarge;},},
This resolver obtains a large or small patch from mission, which is the object returned by the default resolver for the parent field in our schema, Launch.mission.
Now that we know how to add resolvers for types besides Query, let's add some resolvers for fields of the Launch and User types. Add the following to your resolver map, below Mission:
// Mission: {// ...// },Launch: {isBooked: async (launch, _, { dataSources }) =>dataSources.userAPI.isBookedOnLaunch({ launchId: launch.id }),},User: {trips: async (_, __, { dataSources }) => {// get ids of launches by userconst launchIds = await dataSources.userAPI.getLaunchIdsByUser();if (!launchIds.length) return [];// look up those launches by their idsreturn (dataSources.launchAPI.getLaunchesByIds({launchIds,}) || []);},},
You might be wondering how our server knows the identity of the current user when calling functions like getLaunchIdsByUser. It doesn't yet! We'll fix that in the next chapter.
Paginate results
Currently, Query.launches returns a long list of Launch objects. This is often more information than a client needs at once, and fetching that much data can be slow. We can improve this field's performance by implementing pagination.
Pagination ensures that our server sends data in small chunks. We recommend cursor-based pagination for numbered pages, because it eliminates the possibility of skipping an item or displaying the same item more than once. In cursor-based pagination, a constant pointer (or cursor) is used to keep track of where to start in the data set when fetching the next set of results.
Let's set up cursor-based pagination. In src/schema.js, update Query.launches to match the following, and also add a new type called LaunchConnection like so:
type Query {launches( # replace the current launches query with this one."""The number of results to show. Must be >= 1. Default = 20"""pageSize: Int"""If you add a cursor here, it will only return results _after_ this cursor"""after: String): LaunchConnection!launch(id: ID!): Launchme: User}"""Simple wrapper around our list of launches that contains a cursor to thelast item in the list. Pass this cursor to the launches query to fetch resultsafter these."""type LaunchConnection { # add this below the Query type as an additional type.cursor: String!hasMore: Boolean!launches: [Launch]!}
Now, Query.launches takes in two parameters (pageSize and after) and returns a LaunchConnection object. The LaunchConnection includes:
- A list of
launches(the actual data requested by a query) - A
cursorthat indicates the current position in the data set - A
hasMoreboolean that indicates whether the data set contains any more items beyond those included inlaunches
Open src/utils.js and check out the paginateResults function. This is a helper function for paginating data from the server.
Now, let's update the necessary resolver functions to accommodate pagination. Import paginateResults and replace the launches resolver function in src/resolvers.js with the code below:
const { paginateResults } = require("./utils");module.exports = {Query: {launches: async (_, { pageSize = 20, after }, { dataSources }) => {const allLaunches = await dataSources.launchAPI.getAllLaunches();// we want these in reverse chronological orderallLaunches.reverse();const launches = paginateResults({after,pageSize,results: allLaunches,});return {launches,cursor: launches.length ? launches[launches.length - 1].cursor : null,// if the cursor at the end of the paginated results is the same as the// last item in _all_ results, then there are no more results after thishasMore: launches.length? launches[launches.length - 1].cursor !==allLaunches[allLaunches.length - 1].cursor: false,};},},};
Let's test the cursor-based pagination we just implemented. Restart your server with npm start and run this query in Apollo Sandbox:
query GetLaunches {launches(pageSize: 3) {launches {idmission {name}}}}
Thanks to our pagination implementation, the server should only return three launches instead of the full list.
That takes care of the resolvers for our schema's queries! Next, let's write resolvers for our schema's mutations.