We took a shortcut to server-land with GraphOS Studio, where we saw queries succeed and fail. Now how about we make sure the whole round-trip query journey works from our client app, to the server and back?
Let's run the client. Open up a new terminal and navigate to the client folder. Run npm start, which will open up your browser to http://127.0.0.1:3000/, or localhost:3000.
Look at that, our Catstronauts app is showing all of the tracks on the homepage! Well done! Our query's journey is complete.
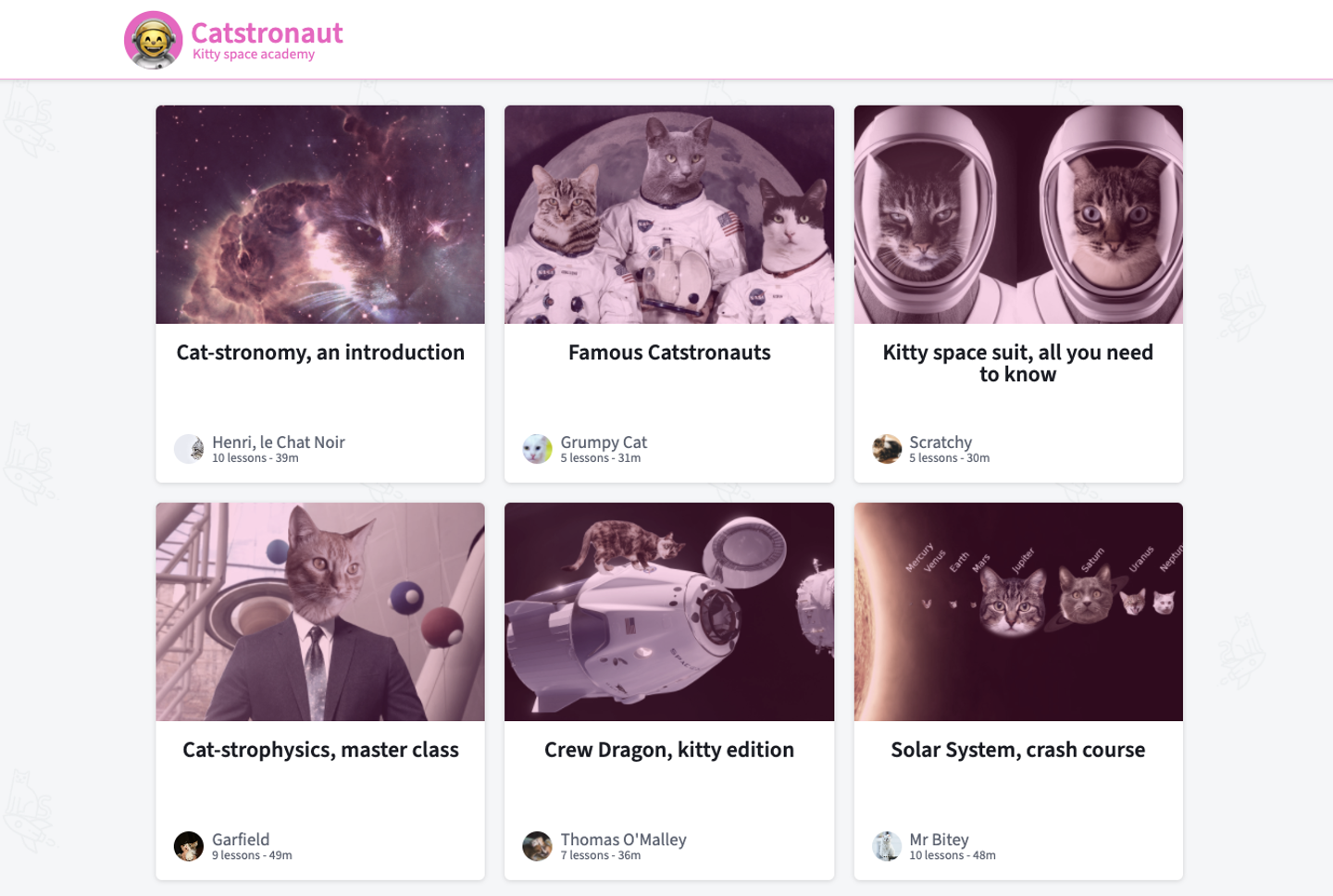
We've come a long way. We retrieved live data from a REST API. We used a RESTDataSource to handle making these API calls more efficient. We created a resolver to connect to that data source and successfully return the correct fields to our client. We even saw what can happen if something went wrong with our query. In the end we got all of the Catstronauts tracks on our homepage.
Have you noticed that we changed our data from mock objects to live data, without needing to modify a thing on the client app? Everything on the client's end kept working as in Lift-off I, but now it's populated with real data.
Although things can and will change (new data sources, new clients, and so on), the graph brings a new level of flexibility and resilience for developers. The schema remains the single source of truth for your data, which your clients can rely on.
In the next mission, Lift-off III, we'll be using query arguments, writing more resolvers, and adding a new Track Details page to our Catstronauts app. See you there!
Share your questions and comments about this lesson
Your feedback helps us improve! If you're stuck or confused, let us know and we'll help you out. All comments are public and must follow the Apollo Code of Conduct. Note that comments that have been resolved or addressed may be removed.
You'll need a GitHub account to post below. Don't have one? Post in our Odyssey forum instead.