Overview
Let's dive into the architecture of a supergraph.
In this lesson, we will:
- Identify the key pieces of a supergraph, what each piece does and where it's hosted
- Describe how a round-trip request and response works from the client to the supergraph
Starting from a GraphQL API
First, let's take a look at how a GraphQL API currently works.
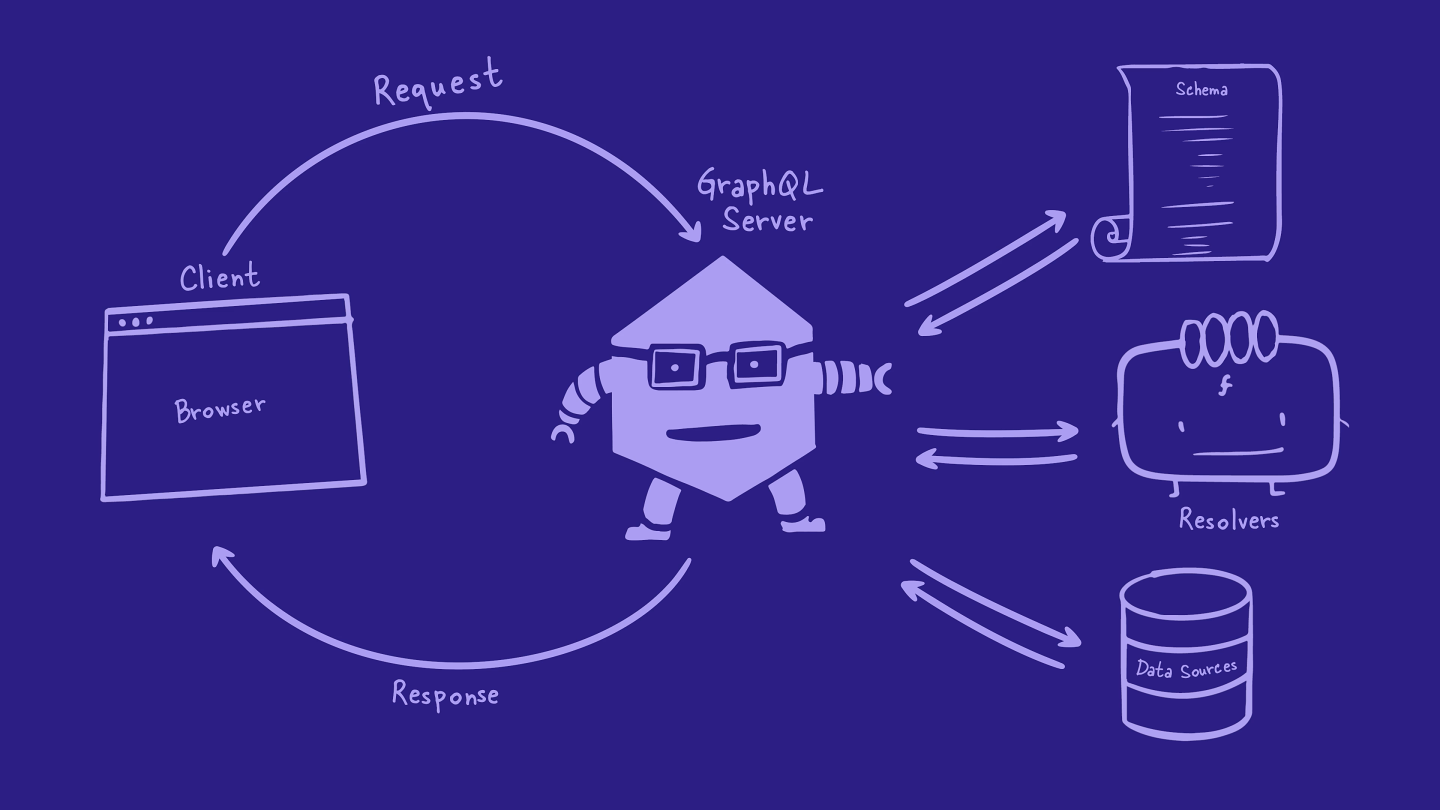
When a client needs some data, it sends a GraphQL operation to the GraphQL server. The server uses its schema, resolvers, and data sources to retrieve and resolve that data, then sends it back to the client. It's a pretty great experience!
This setup works well for smaller projects or teams, but what happens as our API grows? As more teams start adding types, fields, and features to our schema, our API becomes harder to manage, scale, and deploy. This is a common bottleneck problem with monolithic backend services.
To solve this problem, we can divide our API's capabilities across multiple GraphQL-powered microservices, with each one taking responsibility for a different part of our API's schema. When we adopt this federated architecture, each of our microservices is called a subgraph, and together, they form the foundation of our supergraph.
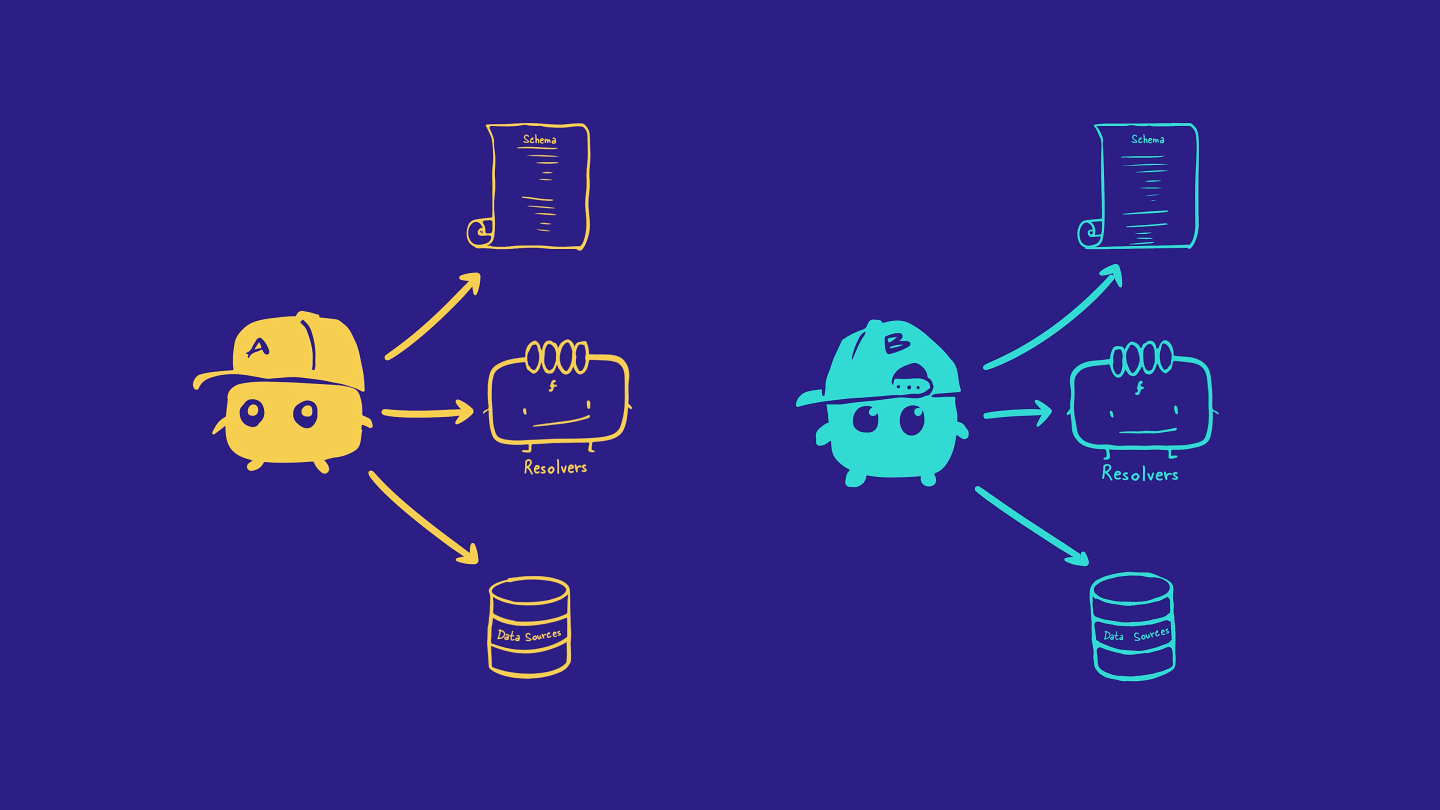
In our case, the Poetic Plates API can become the very first subgraph in our supergraph. It takes responsibility for all of the schema's types and fields about our recipes.
As our supergraph grows, it can include one, two, or even two hundred subgraphs! It all depends on how we want to divide our features and capabilities to help our teams build and collaborate. So our big dreams for Poetic Plates will involve more subgraphs in the future!
This brings us to an important question: If we split our API's capabilities between lots of different microservices, how do clients query across all of them? For that, we need the other piece of our supergraph: the router.
The router knows about all of our subgraphs, and it also knows which subgraph is responsible for each field in our API's schema. Clients send queries to the router, and the router intelligently divides them up across the appropriate subgraphs.
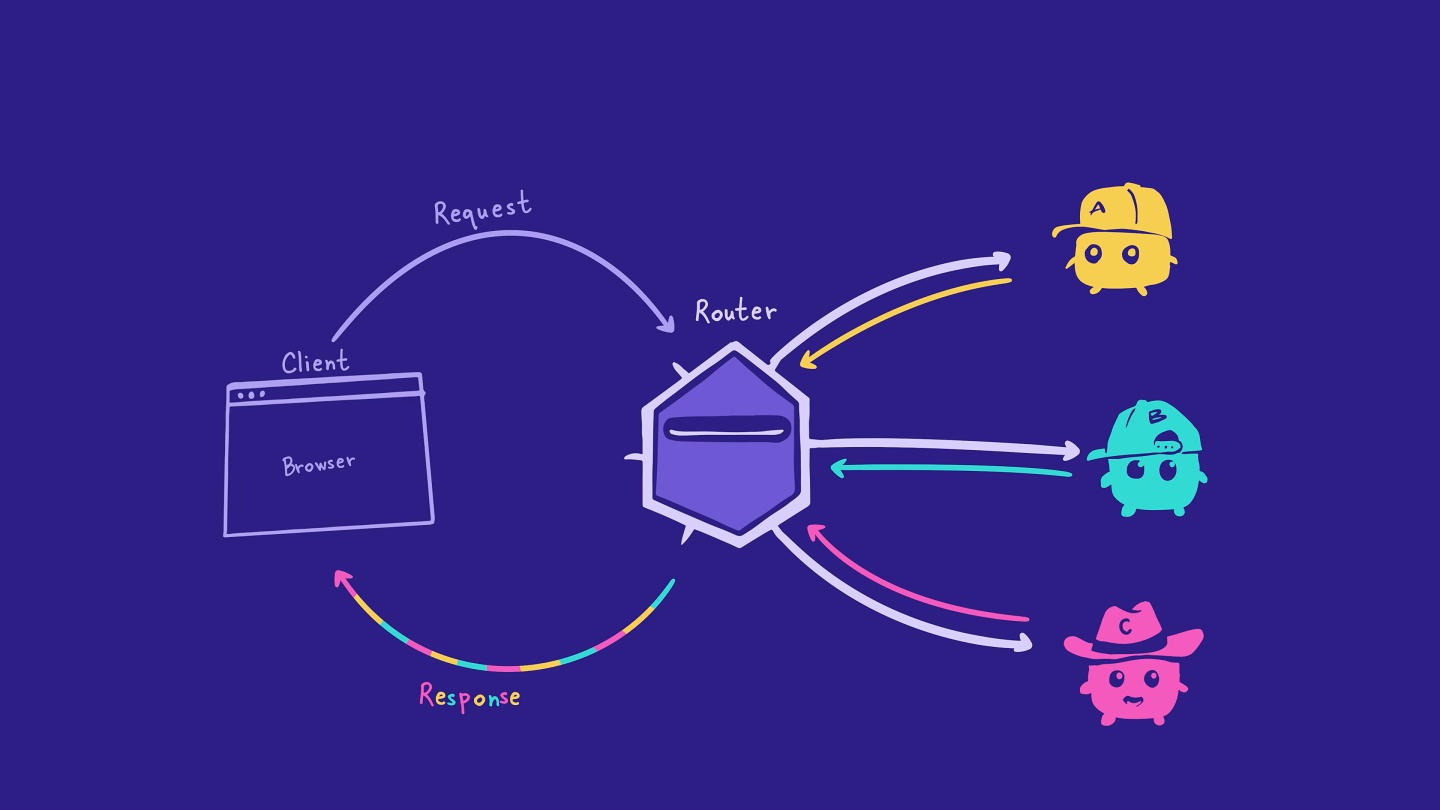
The router acts as the single access point for our API, kind of like an API gateway. This means that clients don't need to worry about communicating with our individual subgraphs!
Where GraphOS fits in
So that's the supergraph! GraphOS is the developer platform that helps us build and manage it.
GraphOS will provision, host and maintain the router for us, which is really handy. If you want to host the router yourself, you can do that too! You can check out the Apollo documentation on how to do so.
On the other hand, we're responsible for hosting our subgraphs. We can use any hosting platform that suits our needs.
We'll provide GraphOS with the URL and schema of our existing GraphQL API, which then becomes the first subgraph in our supergraph. Once it's on GraphOS, we'll get access to awesome features like the schema registry, observability metrics, safe schema delivery and more.
Practice
Key takeaways
- The supergraph architecture is composed of one or more subgraphs and a router.
- The client sends a GraphQL operation to the router. The router receives this request, figures out which subgraphs are responsible for resolving it, and sends the operations to the appropriate subgraphs. The subgraphs resolve the data and return it to the router, which then bundles it up to return to the client.
Up next
Grab your coding aprons, it's time to cook up a supergraph.
Share your questions and comments about this lesson
Your feedback helps us improve! If you're stuck or confused, let us know and we'll help you out. All comments are public and must follow the Apollo Code of Conduct. Note that comments that have been resolved or addressed may be removed.
You'll need a GitHub account to post below. Don't have one? Post in our Odyssey forum instead.