

As part of NerdWallet’s migration from our React-Redux code base to client state management using Apollo, we’ve been exploring how to effectively implement data access patterns, side-effects handling, and other aspects of client state management using GraphQL and Apollo Client.
This first post examines how we accomplish effective data access, filtering and transformation on the client like we currently do using Redux selectors. Our goal is to not only find an Apollo equivalent to what we were able to achieve with Redux selectors, but also make sure that it is a step forward in effectively managing our client side data.
While we’ll briefly touch on where we’re coming from with Redux, the solutions are all Apollo-based and applicable to any project using Apollo regardless of their familiarity with Redux or other state management solutions.
Coming from Redux
Our organization has made heavy use of Redux selectors to manage client-side data access and over the years we’ve built up hundreds of selectors that we use in various combinations across our applications. For those who are unfamiliar with Redux selectors, you can read about them here.
Redux isn’t a very complicated library, it essentially boils down to a single object {} that stores all of your application’s state and you can dispatch actions to update that global state object however you want. You have complete control over the shape of that global state object. Selectors are just utility functions that read, aka select, data from that global state object.
For example, your Redux state might look like this:
1{2 employees: [3 { id: 1, name: 'Alice', role: 'Manager', team: 'Banking' },4 { id: 2, name: 'Bob', role: 'Senior Developer', team: 'Investments' },5 ]6}in which case a Redux selector could perform a data access like this:
1const getEmployees = (state) => state?.employees ?? [];or filter the data down like this:
1const getBankingEmployees = (state) => getEmployees(state).filter(employee => employee.team === 'Banking');2const getManagers = (state) => getEmployees(state).filter(employee => employee.role === 'Manager');As we can see, selectors are composable, so our applications often make use of chaining them together:
1import _ from 'lodash';23const getBankingManagers = (state) => _.intersection(getManagers(state), getBankingEmployees(state));Selectors make it easy tools to access the data we need in the shape that we want. Now let’s compare the tools Apollo gives us to accomplish this same goal.
Moving to Apollo
Apollo models its client state using a normalized client-side cache. There’s a great post from their team on what this means and how it works, which I’d recommend folks check out before we get too deeply in the weeds here.
1{2 'Employee:1': {3 __typename: 'Employee',4 id: 1,5 name: 'Alice',6 role: 'Manager',7 team: 'Banking',8 },9 'Employee:2': {10 __typename: 'Employee',11 id: 1,12 name: 'Bob',13 role: 'Senior Developer',14 team: 'Investments',15 },16 ROOT_QUERY: {17 employees: {18 __typename: 'EmployeesResponse',19 data: [20 { __ref: 'Employee:1' },21 { __ref: 'Employee:2' },22 ]23 }24 }25}This is more complicated than how things looked in Redux, so what’s going on here?
Since Apollo is a GraphQL client, data is written to the cache using queries and mutations. Our employees data has been written under an employees field, which could have been generated by a query like this:
1query GetEmployees {2 employees {3 id4 name5 role6 team7 }8}Since Apollo stores data entities using a normalization approach, the data in the cached queries are by reference, not value. We can see the values of these normalized entities adjacent to the ROOT_QUERY, which stores all of the cached responses.
If we wanted to filter down our data to get the managers like we did before, we could write another query like this:
1query GetManagers {2 managers {3 id4 name5 role6 team7 }8}9After this query is executed, the cache would be updated to look like this:
1{2 'Employee:1': {3 __typename: 'Employee',4 id: 1,5 name: 'Alice',6 role: 'Manager',7 team: 'Banking',8 },9 'Employee:2': {10 __typename: 'Employee',11 id: 1,12 name: 'Bob',13 role: 'Senior Developer',14 team: 'Investments',15 },16 ROOT_QUERY: {17 employees: {18 __typename: 'EmployeesResponse',19 data: [20 { __ref: 'Employee:1' },21 { __ref: 'Employee:2' },22 ]23 },24 managers: {25 __typename: 'EmployeesResponse',26 data: [27 { __ref: 'Employee:1' },28 ]29 }30 }31}32Let’s break down the steps it took to do this:
- We dispatched our
GetManagersquery on the client - It went out over the network to our remote GraphQL server
- Our remote server resolved the
managersfield and returned a filtered list of employees - The client cache parsed this response, wrote the managers query to the cache and updated the existing normalized
Employee:1entity
The downside to this approach is that we still hit the network to get our managers when we would have been fine using the existing cached data we had on all of our employees to get a list of managers from them. Making distinct queries over the network for data we already have available in the cache will slow down the experience for our users and introduce unnecessary network burden.
Reading from the Apollo cache
Instead of making a query over the network to our GraphQL server, we can use Apollo 3 field policies to access data directly from the cache.
A field policy, as described by Apollo’s documentation, allows developers to:
customize how a particular field in your Apollo Client cache is read and written.
We could customize how a field of our Employee type is read like this:
1const cache = new InMemoryCache({2 typePolicies: {3 Employee: {4 fields: {5 name: {6 read(name, options) {7 return name.toLowerCase();8 }9 }10 },11 },12 },13});14The first argument is the existing value in the cache, which we can transform as desired. We can even define policies for new fields that aren’t in the schema:
1const cache = new InMemoryCache({2 typePolicies: {3 Employee: {4 fields: {5 isWorkFromHome: {6 read(isWorkFromHome, options) {7 return isPandemicOn;8 }9 }10 },11 },12 },13});14We can then query for this custom field in our queries using the client directive:
1query GetEmployees {2 employees {3 id4 isWorkFromHome @client5 }6}7When Apollo encounters a field marked with the client directive, it knows not to send that field over the network and instead resolve it using our field policies against its cached data.
So far we’ve used field policies to to select data off of particular employee entities, but we still haven’t seen how we can get all of the managers from the cache like we did with Redux.
Root query field policies
In addition to defining new fields on types like Employee, we can also create custom client-side fields by defining fields on the Query type:
1const cache = new InMemoryCache({2 typePolicies: {3 Query: {4 fields: {5 readManagers: {6 read(managers, options) {7 // TODO8 }9 }10 },11 },12 },13});14Our client-side readManagers field will read data from the Apollo cache and transform it into whatever shape we need to represent, achieving the same result as with using selectors. I’ve prefixed the field with read as a convention to make it clear that we’re reading from the client cache rather than resolving a field from our remote GraphQL schema.
So how do we actually read the data we want for our query? We need to use the options.readField API that Apollo provides in the field policy function. The full breakdown of the field policy options are available here in the Apollo docs. The readField API takes 2 parameters, first a fieldName to read from the cache and then the StoreObject or Reference to read it from.
One handy property of the readField API that we can take advantage of is that if you don’t pass a 2nd parameter, it defaults to reading the field from the current object (in this case, the ROOT_QUERY object). This allows us to read existing fields from our new one:
1const cache = new InMemoryCache({2 typePolicies: {3 Query: {4 fields: {5 readManagers: {6 read(managers, { readField }) {7 const employees = readField('employees');8 // Output:9 // {10 // __typename: 'EmployeesResponse',11 // data: [12 // { __ref: 'Employee:1' },13 // { __ref: 'Employee:2' },14 // ]15 // }16 return (employees?.data ?? []).filter(employeeRef => {17 const employeeRole = readField('role', employeeRef);18 return employeeRole === 'Manager';19 });20 }21 }22 },23 },24 },25});26Let’s break down the pattern for writing our client side query into steps:
- First we defined a new field policy called
readManagerson theQuerytype. - Then we read the existing
employeesfield from the cache using thereadFieldfield policy API. - Next we iterated over the employees from that cached query.
- For each of those employees, we used the
readFieldpolicy again to read theirrolefrom the employee reference. - If their role is a manager, we returned that employee.
Putting it all together, we’re now able to query for our managers anywhere we want in our application using a query like this:
1query GetManagers {2 readManagers @client {3 id4 name5 }6}7Canonical fields
In our example, we filtered down our list of managers from the cached employees field. This is what I call a canonical field, a field that represents the entire collection of a particular type on the client from which custom filters and views of that data are derived.
Without a canonical field, it is much more difficult to support client-side data filtering and transformations. Consider a scenario where instead of an employees field, our remote schema had separate bankingEmployees, investmentEmployees, managers and engineers fields that we’ve queried for and written to the cache.
This modeling makes it difficult to handle scenarios like adding or deleting an employee from the system. The employee might be a manager on the banking team, requiring us to update both the cached bankingEmployees and managers queries.
It also makes it difficult to build client-side fields that are supersets of these fields, like if a part of our application wants to list out all employees. We would need to write a new field policy that reads all four of these fields and de-duplicates employees that exist across them.
By using a canonical field like employees that is kept up to date with all instances of a particular entity, we can more easily manage derived fields that represent subsets and transformations on the collection.
Field policy composition
Client-side field policies can easily be composed together similarly to how we demonstrated with Redux. To get all banking managers like we did in the Redux example, we can write a set of field policies like this:
1const cache = new InMemoryCache({2 typePolicies: {3 Query: {4 fields: {5 readEmployees: {6 read(employees, { readField }) {7 return readField('employees')?.data ?? [];8 },9 },10 readManagers: {11 read(managers, { readField }) {12 return readField('readEmployees').filter(employeeRef => {13 const employeeRole = readField('role', employeeRef);14 return employeeRole === 'Manager';15 });16 }17 },18 readBankingTeam: {19 read(managers, { readField }) {20 return readField('readEmployees').filter(employeeRef => {21 const employeeTeam = readField('team', employeeRef);22 return employeeTeam === 'Banking';23 });24 }25 },26 readBankingManagers: {27 read(bankingManagers, { readField }) {28 return _.intersection(29 readField('readManagers'),30 readField('readBankingTeam')31 );32 }33 }34 },35 },36 },37});38As we can see in this example, our new field policies can reference each other, making it easy to compose them together to create other field policies as needed. I created a readEmployees field policy that parses out the data of the raw employees field from the GraphQL server so that we don’t need to keep doing that in every other field policy.
Field policies with arguments
Instead of having to write a different field policy for each team of employees, it would be handy if we could provide the team to filter by to a single field policy. Field policies support arguments just like any other field, which we can provide as shown below:
1const cache = new InMemoryCache({2 typePolicies: {3 Query: {4 fields: {5 readEmployees: {6 read(employees, { readField }) {7 return readField('employees')?.data ?? [];8 },9 },10 readTeamByName: {11 read(managers, { readField, args }) {12 const { teamName } = args;1314 return readField('readEmployees').filter(employeeRef => {15 const employeeTeam = readField('team', employeeRef);16 return employeeTeam === teamName;17 });18 }19 },20 readBankingTeam: {21 read(bankingTeam, { readField }) {22 return readField({ fieldName: 'readTeamByName', args: { teamName: 'Banking' } });23 }24 }25 },26 },27 },28});29As demonstrated in the readBankingTeam field policy, we can use an alternative object parameter to the readField API in order to pass any variables we need when reading that field. A query on this field would then look like this:
1query GetTeamByName($teamName: String!) {2 readTeamByName(teamName: $teamName) @client {3 id4 name5 }6}Adding type safety
For complex applications with a large number of field policies, it is important to have type safety guarantees for the fields we are reading and the shape of the policy return values. It is especially easy to make a typo on the name of the field you’re reading and cause hard to find errors down the road.
We added type safety to our field policies using the GraphQL code generator library, which will generate TypeScript types for each type in your GraphQL schema and each of your queries.
Assuming our Employee type looked like this in our GraphQL schema:
1enum EmployeeRole {2 Manager3 Developer4 SeniorDeveloper5}67enum EmployeeTeam {8 Banking9 Investments10}1112type Employee {13 id: ID!14 name: String!15 team: EmployeeTeam!16 role: EmployeeRole!17}18We would get a generated type looking like this:
1export type Employee = {2 id: Scalars['ID'],3 name: Scalars['String'],4 team: EmployeeTeam,5 role: EmployeeRole,6}7It will define separate types for all enums and referenced GraphQL schema types and additionally if we are using the Apollo helpers plugin, we’ll also get types for our field policies that look like this:
1export type TypedTypePolicies = TypePolicies & {2 Query?: {3 keyFields?: false | QueryKeySpecifier | (() => undefined | QueryKeySpecifier),4 queryType?: true,5 mutationType?: true,6 subscriptionType?: true,7 fields?: QueryFieldPolicy,8 },9};1011export type QueryFieldPolicy = {12 readManagers?: FieldPolicy<any> | FieldReadFunction<any>,13 ...14}15At this time, the plugin isn’t perfect, as we can see that it uses the any type for the field policies and doesn’t know things like what variables they might take, but they will come in handy nevertheless as we’ll see later on.
Now that we have types for our entities, we need to add these constraints to the readField API. Since Apollo does not know that we have generated types for our queries, or even that we are using TypeScript in general, the readField API does not know that when we call readField('readEmployees'), we will be getting back a list of employees, so we need to type that ourselves:
1import { Employee, EmployeeRole } from './generated-types';23const cache = new InMemoryCache({4 typePolicies: {5 Query: {6 fields: {7 readManagers: {8 read(employees, { readField }) {9 const employees = readField<Employee[]>('readEmployees');1011 return employees.filter(employeeRef => {12 const employeeRole = readField<EmployeeRole>('role', employeeRef);13 return employeeRole === 'Manager';14 });15 },16 },17 }18 }19 }20});21But wait! This is not actually the correct typing for readField('readEmployees') because as we know, cached queries contain references. So a correct typing would be readField<Reference[]>('readEmployees') with Reference being imported from @apollo/client.
While this typing is correct, it isn’t very helpful because we would need to know what the return value is for readEmployees to know that it returns an array and we’re still not getting type safety that the field readEmployees actually exists.
Adding field policies to the schema
In order to get better type safety, we need to add your custom fields to the GraphQL schema. We can do this by defining type policy configs which closely our GraphQL server’s remote schema resolvers:
1import { DocumentNode } from 'graphql';2import { gql } from '@apollo/client';3import { TypedTypePolicies } from './generated-types';45interface TypePoliciesSchema {6 typeDefs?: DocumentNode;7 typePolicies: TypedTypePolicies;8}910const schema: TypePoliciesSchema = {11 typeDefs: gql`12 extend type Query {13 readManagers: [Employee!]!14 }15 `,16 typePolicies: {17 Query: {18 fields: {19 readManagers: {...},20 readManagerss: {...} // Typo reports a TSC error21 }22 }23 }24}25The TypedTypePolicies type from earlier has come in handy here, as we now get type safety around the keys and options passed to our field policy. In order to make Apollo and the codegen aware of these schema definitions, we just pass them into the typeDefs option when instantiating our Apollo client:
1import EmployeeTypePoliciesSchema from './employee-type-policies';23const apolloClient = new ApolloClient({4 ...5 typeDefs: [EmployeeTypePoliciesSchema.typeDefs],6});7We’re still not quite there though in terms of implementing thorough type safety. Our next step involves defining a few custom utility types and helpers:
1type DeepReference<X> = X extends Record<string, any>2 ? X extends { id: string }3 ? Reference4 : {5 [K in keyof X]: DeepReference<X[K]>;6 }7 : X extends Array<{ id: string }>8 ? Array<Reference>9 : X;1011export interface ReadFieldFunction {12 <T, K extends keyof T = keyof T>(13 context: FieldFunctionOptions,14 options: ReadFieldOptions15 ): DeepReference<T[K]>;1617 <T, K extends keyof T = keyof T>(18 context: FieldFunctionOptions,19 fieldName: K,20 from?: Reference | StoreObject | undefined21 ): DeepReference<T[K]>;22}2324export const readField: ReadFieldFunction = (...args) => {25 const [context, ...restArgs] = args;26 return context.readField(...restArgs);27};28The main addition here is the custom readField function. We will use this readField that wraps the one from Apollo to add the rest of our type safety. Let’s see it in action:
1import { DocumentNode } from 'graphql';2import { gql } from '@apollo/client';3import { readField } from './utils';4import { Query, TypedTypePolicies, EmployeeRole } from './generated-types';56interface TypePoliciesSchema {7 typeDefs?: DocumentNode;8 typePolicies: TypedTypePolicies;9}1011const schema: TypePoliciesSchema = {12 typeDefs: gql`13 extend type Query {14 readManagers: [Employee!]!15 }16 `,17 typePolicies: {18 Query: {19 fields: {20 readManagers: {21 read(employees, context) {22 const employees = readField<Query, 'readEmployees'>(context, 'readEmployees');2324 return employees.filter(employeeRef => {25 const employeeRole = readField<Employee, 'role'>(context, 'role', employeeRef);26 return employeeRole === EmployeeRole.Manager;27 });28 },29 }30 }31 }32 }33}34So what’s changed? Now our readField function takes two generic type parameters:
- The type of the object we will be reading from
- the key to be read from that object
Since we have defined our custom fields in the schema, the codegen library will include them in its Query type along with the expected return values. In the case of the readEmployees field used above, it would look like this:
1export type Query = {2 readEmployees: Array<Employee>3}4The last change our readField API makes is modifying the return type. While the Query object is correct that readEmployees would return an array of employee objects as part of a query, in the context of readField we know that these will be references, so our DeepReference recursively converts any types in the Array<Employee> return type into references for us.
Note: The DeepReference utility determines whether an object should be a Reference by the presence of an ID field, which won’t always be correct if your type uses a different set of keys for its ID but this is accurate most of the time depending on your app and 100% of our use cases so far.
This setup now gives us type safety that:
- The fields we access using
readFieldexist on the type we’re reading from - The return value of the
readFieldcall is correctly typed.
These typings can help developers increase their confidence when writing field policies and hopefully lead to fewer bugs, especially in larger applications.
Performance in React
Since like many developers, we use Apollo in the context of a React application, we should also look at the effect our field policy data access approach will have on our application’s performance. First we’ll briefly cover the performance of a typical Redux setup so that we can compare.
Let’s revisit our composite getBankingManagers selector from earlier on:
1import _ from 'lodash';23export const getBankingManagers = (state) => _.intersection(getManagers(state), getBankingEmployees(state));4A typical usage of it in one of our React components could look like this:
1import React from 'react';2import { connect } from 'react-redux';3import { getBankingManagers } from './selectors';45const BankingManagerList = ({ managers }) => {6 return (7 <ul>8 {managers.forEach(manager => <li>{manager.name}</li>)}9 </ul>10 );11});1213const mapStateToProps = (state) => ({14 managers: getBankingManagers(state),15});1617export default connect(mapStateToProps)(BankingManagerList);18But if re-render computation is a performance concern in your component, then there’s a problem here. The Redux docs call out this issue explicitly:
React Redux implements several optimizations to ensure your actual component only re-renders when actually necessary. One of those is a shallow equality check on the combined props object generated by the mapStateToProps and mapDispatchToProps arguments passed to connect. Unfortunately, shallow equality does not help in cases where new array or object instances are created each time mapStateToProps is called
Our getBankingManagers selector returns a new array every time it is evaluated, regardless of whether the managers have changed. To solve this problem, we use the Reselect library in our application.
Reselect provides a createSelector function for memoizing selectors based on their inputs. We can see what it looks like when applied to our getBankingManagers selector below:
1import _ from 'lodash';2import { createSelector } from 'reselect';34const getEmployees = (state) => state?.employees ?? [];5const getBankingEmployees = (state) => getEmployees(state).filter(employee => employee.team === 'Banking');6const getManagers = (state) => getEmployees(state).filter(employee => employee.role === 'Manager');78export const getBankingManagers = createSelector(9 [getBankingEmployees, getManagers],10 (bankingEmployees, managers) => _.intersection(bankingEmployees, managers;11)12Now when an action is fired and Redux reinvokes our getBankingManagers function, it will only recompute if its inputs change. In this case its inputs are the outputs of first running getBankingEmployees and getManagers on the updated Redux state. But now we still have a problem, because those selectors return new arrays every time too!
We’ll need to add even more memoization to our other selectors like this:
1import _ from 'lodash';2import { createSelector } from 'reselect';34const array = [];56const getEmployees = (state) => state?.employees ?? array;7const getBankingEmployees = createSelector(8 [getEmployees],9 employees => employees.filter(employee => employee.team === 'Banking')10);11const getManagers = createSelector(12 [getEmployees],13 employees => employee.role === 'Manager'14);1516export const getBankingManagers = (state) => createSelector(17 [getBankingEmployees, getManagers],18 (bankingEmployees, managers) => _.intersection(bankingEmployees, managers),19)20Now all of our selectors in the chain from getBankingManagers are memoized and the base selector, getEmployees, will return a static array if it has no value. This whole memoization process does add extra overhead when writing selectors so it can be done as necessary. Our application, for example, has hundreds of selectors that we have tried to keep memoized because of performance concerns we’ve encountered in the past.
Given how React-Redux apps can optimize their data accesses in components, let’s compare this behaviour to how component re-renders work for Apollo queries.
useQuery Performance
TLDR: There’s lots of caching and memoization under the hood of the Apollo client that gives our field policies approach good performance out of the box.
Apollo queries are typically wired up in React components using the useQuery React hook. A BankingManagersList component would look something like this:
1import React from 'react';2import { gql, useQuery } from '@apollo/client';34const bankingManagersQuery = gql`5 query ReadBankingManagers {6 readBankingManagers @client {7 id8 name9 }10 }11`;1213const BankingManagersList = ({ managers }) => {14 const { data, loading, error } = useQuery(bankingManagersQuery, { fetchPolicy: 'cache-only' });1516 const managers = data?.readBankingManagers ?? [];1718 return (19 <ul>20 {managers.forEach(manager => <li>{manager.name}</li>)}21 </ul>22 );23});24Assuming we already have the data in the cache for the employees field that readBankingManagers reads from, then when this query is executed our component will re-render with a list of managers. There are still a couple open questions it would be good to answer:
- How does Apollo trigger a re-render of the component when the query completes?
- Will the
useQueryhook re-read data from the cache every time the component re-renders from prop or state changes? - What happens if another query somewhere else in the app is executed? Will our component re-render? What if it affected the data we care about?
To answer these questions, we need to explore the Apollo client implementation. Here’s a basic diagram of the modules of the Apollo client involved in getting a component it’s data:

Let’s breakdown each of these modules by their role in delivering data to our component.
Note: many of these modules do much more than what I’ve listed out here, but I’ve tried to streamline the details to the role they play in getting our component its data. I’m also not an Apollo engineer and I’m sure they could break this down more accurately.
- useBaseQuery:
- The
useQueryhook is just a wrapper around theuseBaseQueryhook. - On first render, it sets up a
QueryDatainstance and passes it aforceUpdatefunction that can be used to trigger re-renders when the data the query cares about changes. - When
forceUpdateis called, it reads the latest data fromQueryDataand re-renders. - It caches the result from
QueryData, only re-rendering whenforceUpdateis called or hook options likevariablesorfetchPolicychanges.
- The
- QueryData:
- Class which maps 1:1 with a query set up in a component.
- Sits between the component and the cache and handles data retrieval for the component.
- On instantiation, its tells the
QueryManagerto set up awatchQueryon the GraphQL document that the component cares about and subscribes to changes to the observable returned bywatchQuery.
- Gatekeeps what data the component receives, only telling the query to update if the data the cache sends it passes a deep equality diff.
- QueryManager:
- Manages all query subscriptions across the application setup through the
watchQueryAPI. - When
watchQueryis called, it creates aQueryInfoobject, passing it the GraphQL document fromQueryDataas well as an observable thatQueryInfocan notify when data related to the document has changed in the cache. It returns this observable toQueryDataso that it can receive updates. - Maintains a map of all active
QueryInfoobjects by query ID.
- Manages all query subscriptions across the application setup through the
- QueryInfo:
- Watches changes to the Apollo cache by calling
cache.watch, passing the cache its query document so that the cache can deliver it diffs of the data it cares about. - When the diff against the cache is dirty, it notifies the observable set up by the
QueryManagerand sends it the new data.
- Watches changes to the Apollo cache by calling
- Cache:
- The cache maintains all query and mutation responses as well as the normalized data entities.
- Whenever it is written to, it broadcasts that data has changed to all watchers that might be dirty.
Now that we have identified the core modules involved in querying for data from our component, let’s see what happens when the query we set up in BankingManagerList comes back from the network:
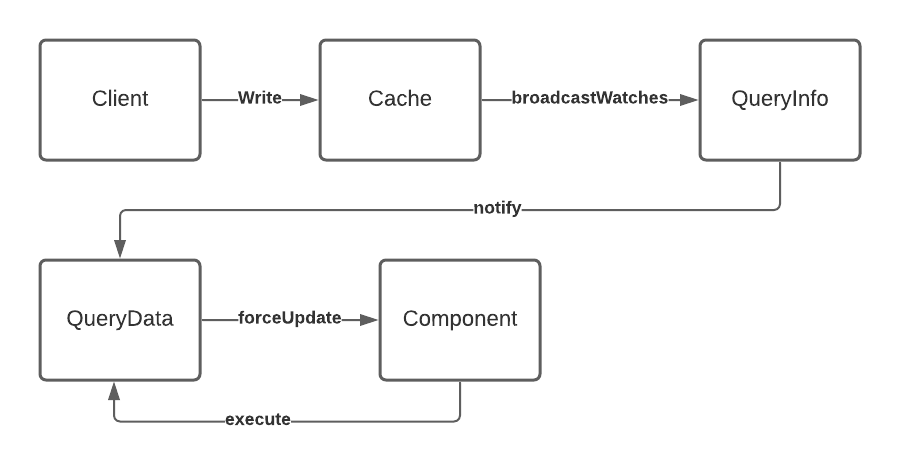
- Firstly, the data from the network is written into the cache by the
cache.writeAPI. - The
writeAPI callsbroadcastWatches()to let subscribed watchers of the cache know that there has been a change. broadcastWatchescallsmaybeBroadcastWatchfor each watcher, which will filter down the list of watchers to only the ones that might be dirty (more on how it determines this later).- For each
QueryInfowatcher that might be dirty, the cache calls theQueryInfo’s provided callback with a cache diff for its query document. - If the diff from the cache is shallowly different, the
QueryInfoinstance notifies the observable set up by theQueryManager. - The
QueryDatasubscribed to this observable receives the diff and performs a deep equality check against its current data to see if it should tell the component toforceUpdate. - When
forceUpdateis called, the component re-renders and callsQueryData.executeto read the new data waiting for it.
Let’s revisit the three questions we wanted to explore:
- How does Apollo trigger a re-render of the component when the query completed?
- We’ve now gone through how this works.
- Will the
useQueryhook read data from the cache every time the component re-renders from prop or state changes?- Nope! It will only re-read data if
forceUpdateis called or the options to the hook change.
- Nope! It will only re-read data if
- What happens if another query somewhere else in the app is executed? Will our component re-render? What if it affected the data we care about?
- We now know that when another query triggers a cache write, the cache will broadcast to watchers that might be dirty. Let’s look at what that means.
Apollo cache dependency graph
If Apollo stopped optimizing accessing cached data as we understand the system so far, then whenever the cache was written to, it would calculate diffs for all of its watchers which includes a watcher for each component using useQuery. This could have performance implications if we have a lot of components using useQuery across our application.
To get around this problem, Apollo uses a dependency graph that tracks the dependencies of a field as they are read. Let’s look at our readBankingManagers field policy again:
1readBankingManagers: {2 read(bankingManagers, { readField }) {3 return _.intersection(4 readField('readManagers'),5 readField('readBankingTeam')6 );7 }8}9When Apollo reads the readBankingManagers field, it records all field names that were resolved as part of evaluating that field as dependencies. In this case it would include the readManagers and readBankingTeam fields. These dependencies are tracked using the Optimism reactive caching developed by Apollo’s core developers.
When we execute a query like this:
1query GetBankingManagers {2 readBankingManagers {3 id4 name5 }6}7and have the following data in the cache:
1{2 'Employee:1': {3 __typename: 'Employee',4 id: 1,5 name: 'Alice',6 role: 'Manager',7 team: 'Banking',8 },9 'Employee:2': {10 __typename: 'Employee',11 id: 1,12 name: 'Bob',13 role: 'Senior Developer',14 team: 'Investments',15 },16 ROOT_QUERY: {17 employees: {18 __typename: 'EmployeesResponse',19 data: [20 { __ref: 'Employee:1' },21 { __ref: 'Employee:2' },22 ]23 },24 managers: {25 __typename: 'EmployeesResponse',26 data: [27 { __ref: 'Employee:1' },28 ]29 }30 }31}32We will get a dependency graph for this query that looks like this:
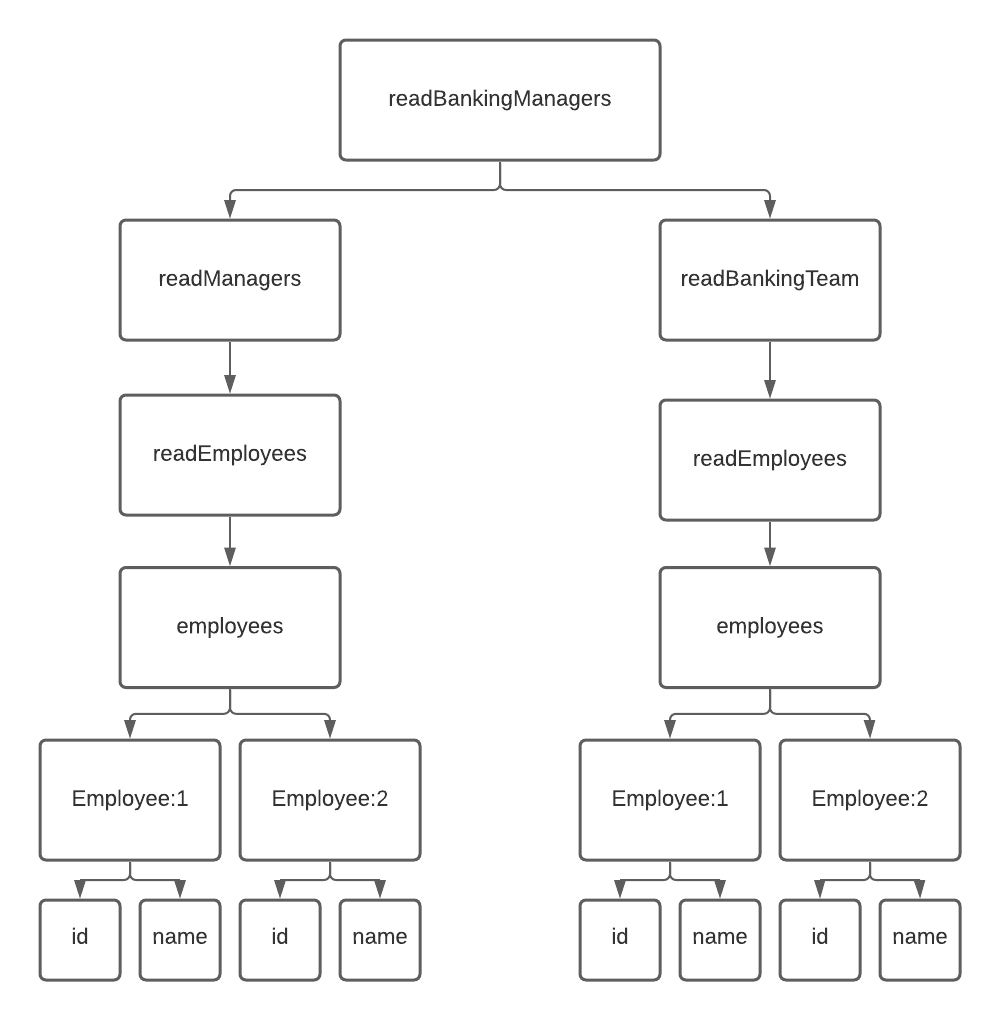
Now let’s consider a couple scenarios:
- The name of
Employee:1is updated
When the cache calls broadcastWatches after writing the new name, the dependency graph for GetBankingManagers will be dirty, so it proceeds with diffing the query against the updated cache and delivering that data to the QueryData instance. If that name is different from what is was previously, QueryData will tell the component to forceUpdate.
2. A new manager is added to the cache using writeFragment
1client.writeFragment({2 data: {3 __typename: 'Employee',4 id: 3,5 name: 'Charles',6 role: 'Manager',7 team: 'Banking',8 },9 id: 'Employee:3',10 fragment: gql`11 fragment NewEmployee on Employee {12 id13 name14 role15 team16 }17 `,18});19When a new employee is written to the cache using writeFragment, none of the fields in our dependency graph have been affected since it is not included in any of our employees responses and only exists as a normalized entity. The subsequent call to broadcastWatches would therefore skip over re-calcuating the diff for the GetBankingManagers query.
3. The new manager is then added to the employees field
1client.modify({2 fields: {3 employees: (currentEmployeesResponse) => {4 return {5 ...currentEmployeesResponse,6 data: [7 ...currentEmployeesResponse.data,8 { __ref: 'Employee:3' },9 ]10 }11 }12 }13});14When the new manager is written into the employees field, the dependency graph for the field is dirtied and now when broadcastWatches is called, the cache will re-calculate the diff for the employees field and deliver it to QueryData. QueryData will do a deep equality check on the diff and see that there is a new employee, telling the component to update.
Reflecting on the breakdown of the Apollo caching mechanisms and these examples, we can see that Apollo offers powerful built-in performance optimizations that eliminate the need for the sort of client-side memoization akin to what we had to do with Redux selectors.
Testing field policies
We’ve spent a good chunk of time writing field policies and now we need to see how to test them. Given the number of selectors in our applications and the number of field policies we’ll need, it’s critical that they be easily testable to support an effective migration and future development.
Let’s see how we can test our bankingManagers policy. We’ll use jest syntax here but it’s all pretty testing library agnostic:
1import typePolicies from './type-policies';2import { InMemoryCache, gql } from "@apollo/client";34describe('employees field policies', () => {5 let cache: InMemoryCache;67 beforeEach(() => {8 cache = new InMemoryCache({9 typePolicies,10 });11 });1213 describe('bankingManagers', () => {14 test('should return employees with role `manager` and team `banking`', () => {15 cache.writeQuery({16 query: gql`17 query WriteEmployeees {18 employees {19 id20 name21 team22 role23 }24 }25 `,26 data: {27 employees: {28 __typename: 'EmployeesResponse',29 employees: [30 {31 __typename: 'Employee',32 id: 1,33 name: 'Alice',34 role: 'Manager',35 team: 'Banking',36 },37 {38 __typename: 'Employee',39 id: 2,40 name: 'Bob',41 role: 'Senior Developer',42 team: 'Investments',43 },44 ],45 },46 },47 });4849 expect(50 cache.readQuery({51 query: gql`52 query {53 readBankingManagers @client {54 id55 }56 }57 `,58 })59 ).toEqual({60 readBankingManagers: [61 {62 __typename: 'Employee',63 id: 1,64 },65 ],66 });67 })68 });69})70As we can see, testing field policies can be accomplished in three basic steps:
- Set up the Apollo cache with your field policies before the tests.
- Write the data needed for the test case to the cache using
cache.writeQuery. - Read the field being tested from the cache using
cache.readQueryand assert that it returns the correct data.
Queries and test data can be shared across tests, making the testing experience pretty simple and straightforward.
Adopting field policies
The goal of this post was to demonstrate how field policies can be used for data access by teams starting out with or migrating to Apollo from other libraries like Redux. We’ve dug into the problems that field policies solve, how they can be composed together, how to safely type them, what their performance implications are, and their testability.
We will revisit the topic again in the future as we expand our usage of field policies in our applications to provide further learnings. Hopefully this breakdown has empowered teams to feel confident using these policies to manage access of their client-side data and made the integration of Apollo to their client tech stack a little clearer.
If you have questions or would like to follow up, feel free to reach out on Twitter. That’s it for now!