Every Token Counts: Building Efficient AI Agents with GraphQL and Apollo MCP Server

Matt Hawkins
When you’re building AI Agents, you’re not just writing code–you’re managing a scarce resource: the context window. Every interaction between your agent and an LLM consumes tokens, and these tokens translate directly into costs, latency, and limitations on what your agent can accomplish.
Consider what happens when an AI agent needs to fetch data from your APIs. The agent must:
- Understand which tool to use (consuming tokens for tool name, descriptions.)
- Know what inputs to provide (more tokens for input schemas)
- Process the response data (potentially lots of tokens for verbose API responses)
Traditional REST APIs return fixed response shapes—your agent gets all the data whether it needs it or not. You could write custom code to transform responses and minimize token usage, but this adds complexity and slows down iteration in what’s typically a fast-moving, experimental workflow.
Why GraphQL Makes Sense Here
This is actually the exact problem GraphQL was designed to solve back in 2012. Unlike REST endpoints that return predetermined structures, GraphQL lets you query for only the fields you need.
For AI agents, this matters because:
- You’re not wasting tokens on fields you don’t use (e.g., getting just
user.nameinstead of a full user object with timestamps, IDs, preferences, etc.) - You can fetch related data in a single request instead of making multiple API calls
- The query itself documents what data you’re using, which helps when you’re debugging why your agent is behaving oddly
And here’s the thing—you don’t have to rewrite your existing REST APIs. GraphQL works fine as a layer on top of what you already have. We’ve been doing this at Apollo for years with enterprise customers who have hundreds of REST services.
How Apollo MCP Server Fits In
We built the Apollo MCP Server to make GraphQL operations, the queries and mutations, work directly as MCP tools.
No manual tool definitions. No boilerplate. No more bespoke backend-for-frontend layers. The GraphQL operation IS the tool definition.
The workflow is straightforward with our just released Operations Collections to MCP Tools capability:
- Write and test your GraphQL operations in Apollo Explorer
- Save them to your MCP Tools Operation Collection
- The Apollo MCP Server automatically exposes them as MCP tools
This builds on Apollo MCP Server’s existing capabilities to create tools from your GraphQL schema, giving you multiple approaches to define your AI agent experiences. Whether you’re exposing your entire graph or crafting specific operations for specific use cases, you’re always in control of what data flows through that precious context window.
If you’re starting from REST APIs, Apollo Router and our REST connectors let you build a GraphQL layer without touching your existing services. This isn’t some magical abstraction—it’s just mapping REST responses to GraphQL types and letting the router handle the orchestration.
The end result: your agents use fewer tokens, you write less code, and you can iterate on tool definitions without redeploying anything. (If you want more context on why GraphQL and MCP are a good fit, check out The Future of MCP is GraphQL.)
MCP Tools and the Context Window
To understand how to optimize token usage, let’s first examine what actually consumes tokens in an MCP tool. An MCP server provides the following metadata about each tool:
- The tool name
- A description of the tool. This allows the LLM to determine when it’s appropriate to use this tool. The description may also be shown to end users by some MCP clients
- An input schema. This is a JSON Schema describing the information the LLM needs to provide to the tool
- Annotations. These are optional fields that provide additional information on behavior that the MCP client may use
The MCP tool will execute in the “context window” of the AI agent. This is a limited amount of memory that the agent has to keep information relevant to the current conversation. The limit is measured in tokens. Depending on the payment plan the user has with their AI provider, token usage also typically counts toward the cost of using the AI agent. The more tokens used, the higher the cost, and the user may be capped at a certain token limit.
The tool metadata described above counts toward the token usage, as does the input to and response from each call to the tool. The more efficient the tool can be with its token usage, the more context window space will be available for the user’s conversation with the agent, the lower the end user’s AI costs will be, and the quicker the user’s prompt will be satisfied. This efficiency requires minimizing:
- The size of the tool metadata
- The size of the request and response each time the tool is invoked
- The number of tool invocations required to satisfy the user’s prompt
There may be some tradeoffs between these – for example, returning less information in a tool response may require the agent to call the tool again to get more data.
When designing an MCP tool, we need to carefully consider the inputs and outputs. We need to be mindful of not just the token impact, but also the data we expect an LLM to be able to provide as input, and the data we want the LLM to have in the response. A critical question is whether the LLM will “understand” this data. If the model can’t determine what it should provide as input, or gets back a response that it can’t interpret, this will likely lead to an unpredictable and confusing interaction with the user.
The Goldilocks Problem of MCP Tools
Beyond optimizing individual operations, there’s another challenge: how many tools should you expose?
Too few tools and the LLM lacks the granularity to help users effectively. Too many tools and you’ve blown your token budget just on tool definitions, plus the LLM gets confused about which tool to use when.
With GraphQL and Apollo MCP Server, finding the right balance is just a matter of writing the right queries:
- Start broad: One operation that fetches multiple related data points
- Notice patterns: The LLM keeps asking follow-up questions about specific data
- Split strategically: Break out frequent requests into focused operations
- Combine when needed: Merge operations that are always called together
For example, you might start with a broad GetWeatherOverview tool, then notice the LLM frequently needs just alerts, so you create a focused GetWeatherAlerts tool. No code changes, no redeployment—just save a new operation.
This iterative refinement is natural with GraphQL. You’re not locked into REST endpoint granularity or forced to write custom tool wrappers. The same GraphQL API can support both a comprehensive tool and a dozen focused ones.
With this flexibility in mind, let’s dive into how GraphQL operations give you precise control over your tools’ inputs and outputs.
Focus on the Data with GraphQL
Using GraphQL and Apollo MCP Server allows you to focus on this important input and output data, rather than the implementation details of how the tool executes. Implementing an MCP tool is just a matter of defining the GraphQL operation that the tool will execute.
Input
Every argument your LLM needs to provide costs tokens – both in the tool description and in every request. GraphQL operations let you control exactly what arguments are exposed and how they’re described.
Start Simple: Minimize What the LLM Needs to Know
Consider this weather alerts operation:
query GetWeatherAlerts($state: String!) {
alerts(state: $state) {
severity
description
instruction
}
}Without guidance, the generated tool description might include verbose schema documentation, and the LLM might not know whether state means “Colorado”, “CO”, or “solid”. Both problems waste tokens.
Add a concise comment to fix both issues:
# Get the weather alerts for a US state, given the two-letter abbrevation for the state.
# Returns a severity, description, and instruction for the alert.
query GetWeatherAlerts($state: String!) {
alerts(state: $state) {
severity
description
instruction
}
}This focused description replaces potentially lengthy auto-generated documentation, saving tokens on every conversation.
Even Better: Eliminate Arguments Entirely
Why make the LLM provide arguments it doesn’t need to? If you’re building an agent for Colorado users, hard-code the value:
# Get the current weather alerts for Colorado.
query GetColoradoWeatherAlerts {
alerts(state: "CO") {
severity
description
instruction
}
}For Existing GraphQL APIs: Taming Verbose Schemas
If your GraphQL schema has detailed descriptions designed for developers, they might balloon your token usage when auto-generated into tool descriptions. The Apollo MCP Server includes all field descriptions by default, which can add up quickly.
Override with concise comments that give LLMs just what they need. You’re not changing your schema – just optimizing how it’s exposed to AI agents.
Another Approach: Pre-fill Variables in Explorer
You can also keep the variable in your operation but pre-fill its value when saving to your Operation Collection:
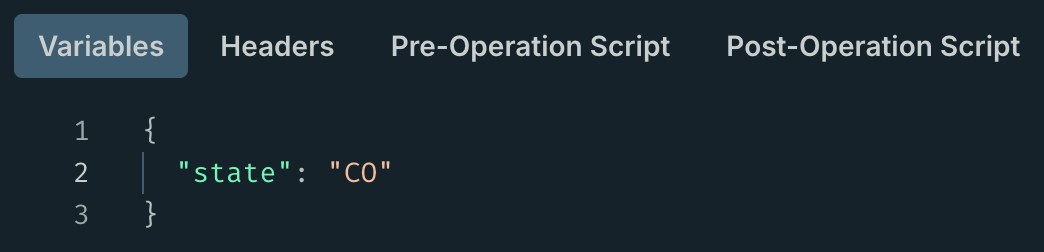
When you save an operation with pre-filled variables, Apollo MCP Server won’t expose them to the LLM at all. This lets you:
- Create multiple tools from one operation (e.g.,
GetCaliforniaAlerts,GetTexasAlerts) - Keep your operations flexible while still optimizing token usage
- Manage tool variants without code duplication
Output
On the output side, GraphQL’s selection sets give you precise control over what data the LLM receives. This doesn’t just help you save tokens—it also helps prevent confusion.
Start with What You Need
Let’s say you want today’s high temperature. A simple request might look like:
# Get today's predicted high temperature
query HighTemperature {
forecast {
temperatures {
high
}
}
}This returns exactly one number. No extra fields, no wasted tokens, no chance for the LLM to get distracted by irrelevant data.
The Cost of Over-Fetching
Now consider what happens if you don’t have this control. Here’s a typical weather forecast schema:
"""A weather forecast"""
type Forecast {
"""The predicated temperatures"""
temperatures: TemperatureRange!
"""A detailed forecast description"""
detailed: String!
"""The URL of an image to show for the day, such as a sun for a sunny day"""
image: String!
}
"""A temperature range"""
type TemperatureRange {
high: Float!
low: Float!
}Without GraphQL’s field selection, you’d get all of this data whether you need it or not. The image URL alone could be 100+ characters. The detailed description might be a paragraph of text. That’s hundreds of tokens for data you don’t need.
Worse, the LLM might start reasoning about these extra fields, potentially confusing users with information about moon phases or UV indexes when they just asked for the temperature.
Using Aliases for Token Efficiency and Clarity
GraphQL aliases offer two powerful benefits for MCP tools: they let you fetch multiple variations of the same data in a single request, and they let you rename fields to be more LLM-friendly.
First, let’s see how we can use aliases to reuse the same field multiple times with different arguments:
# Get the current weather alerts for the West Coast of the US.
query WestCoastWeatherAlerts {
california: alerts(state: "CA") {
severity
description
}
oregon: alerts(state: "OR") {
severity
description
}
washington: alerts(state: "WA") {
severity
description
}
}Aliases can also be used to shorten field names so they use fewer tokens. They can also make the response easier to interpret by the LLM. This is especially useful if our GraphQL schema contains field names that use non-standard abbreviations, or internal terms that an AI model would not have encountered in its training. Aliasing lets us remap these names into something the AI model will be able to work with.
query GetData {
transaction: tx {
id
short: some_really_long_field_name
}
}When creating these aliases, consider the common domain language your end users and the AI model will use in their conversations. You’ll want to consistently refer to items in that domain by the same terms in both field names and tool descriptions, making it simpler for the AI model to associate the user’s prompt with the inputs and outputs of your MCP tool.
Conclusion
Apollo has made creating MCP tools as easy as saving a GraphQL operation in GraphOS. This allows you to focus on the inputs and outputs for your tools, rather than implementation details. You can declaratively define the common language your end users will use in their natural language conversations with AI agents.
With GraphQL’s precision and Apollo’s tooling, you’re not just building AI agents—you’re building token-efficient agents that can maintain longer conversations, cost less to operate, and deliver better user experiences. Every saved token is more context your agent can use to actually help users.
Try out version 0.4.2 or later of the Apollo MCP Server to get started today.